What is a predefined pipeline processor?
Predefined pipeline processors are processors which can be used to execute common tasks.
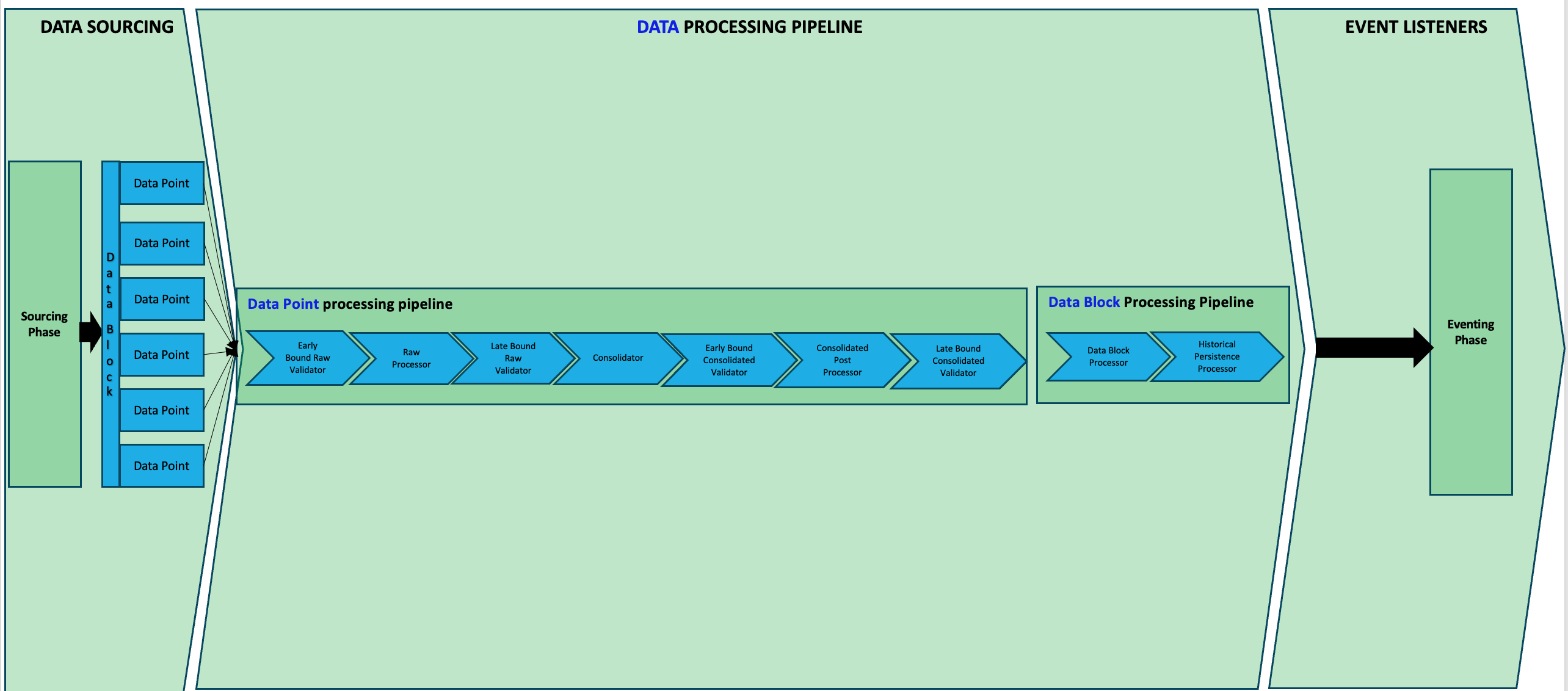
Apiro is able to process data in batch or real time. Data is broken down to Data Blocks (eg. Rows in CSV) and Data Points (eg. Columns in CSV). The diagram below illustrates that each data point can go through an unlimited number of data processors and data blocks also have unlimited number of data processors.
This provides a fine-grained control of how data is processed.
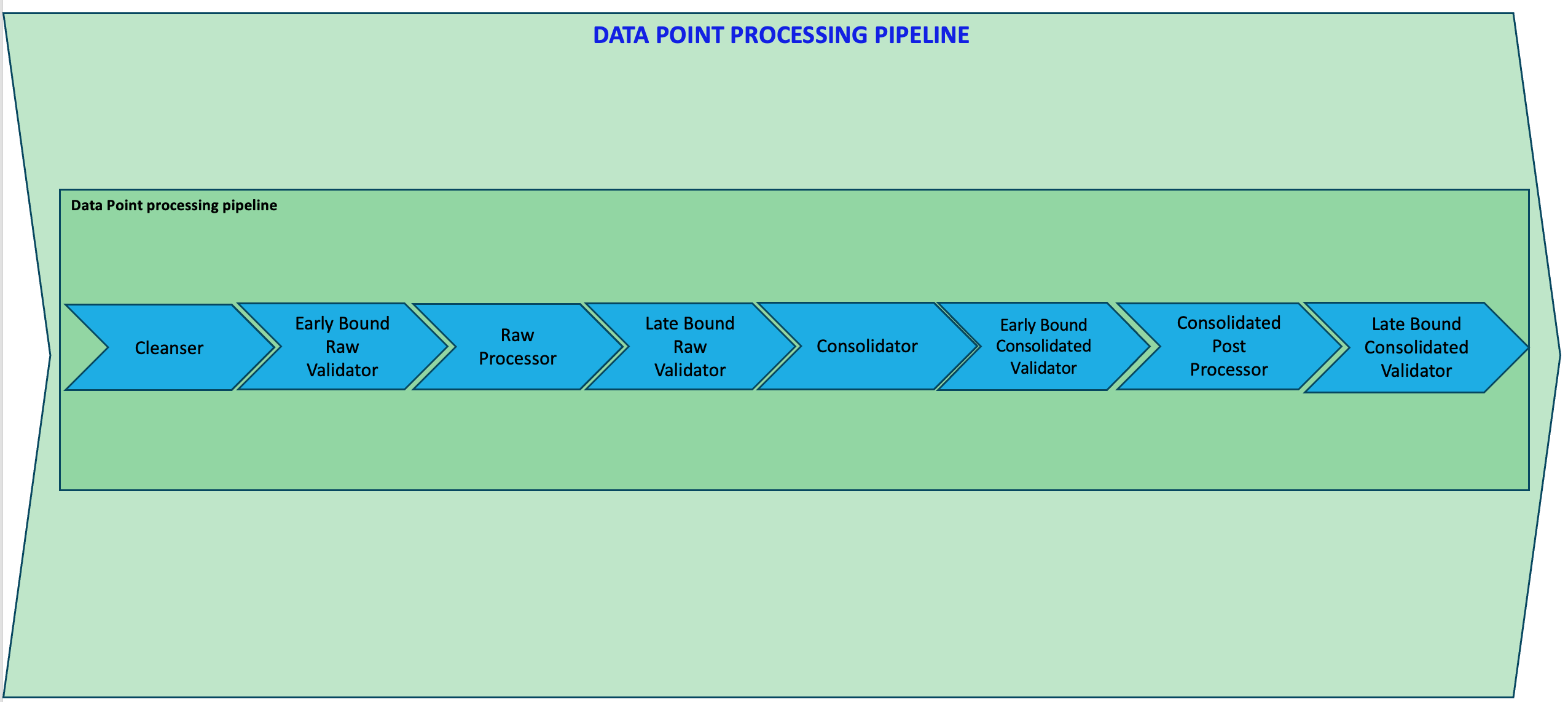
Data Point pipeline?
The diagram below illustrates the pipeline each data block can implement. We can see below that each data point can implement one of the following processors and the processors are executed in the order showened below.
- Cleanser NOTE: A cleanser is not part of the data pipeline. Its purpose is to ensure the data is cleansed before the processing commences.
- Early Bound Raw Validator
- Late Bound Raw Validator
- Consolidator
- Early Bound Consolidated Validator
- Consolidated Post Processor
- Late Bound Consolidated Validator
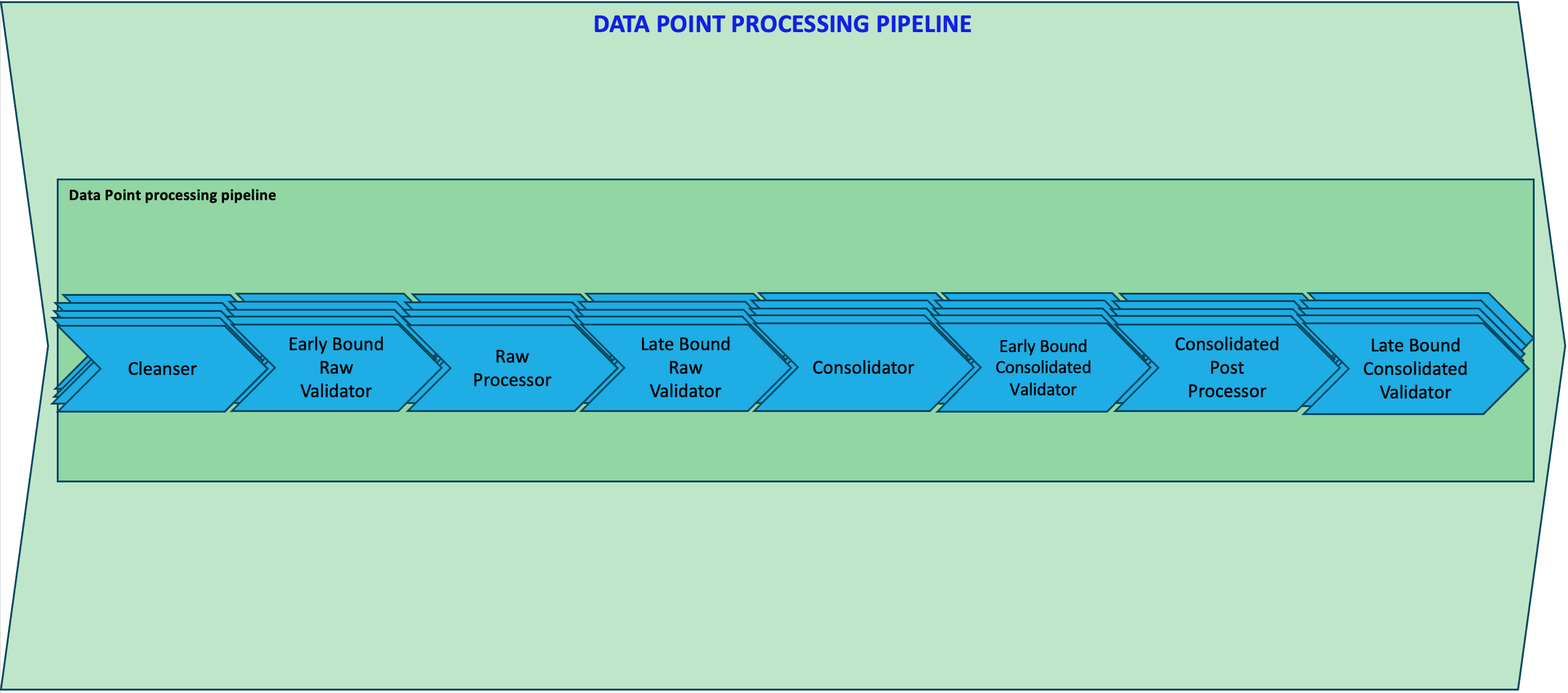
For each type of data processor a list can be provided.
Pipeline Processors in XML format:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |