Section 2 - Create a CUSTOMER schema, by sourcing an excel spreadsheet from GIT using IntelliJ
Go back to Getting started guide
In this section we will:
- Source the Excel file customers_a.xlsx from GIT.
- Create data schema data source, data feed config files.
- Create data pipelines.
- Push all the files into git inline with the GitOps framework.
Notes::
- Apiro config can also be developed manually.
- This is an identical exercise to the previous section Section1 GIT via UI.
- The end result is the same, but we will mainly use Intellij instead of using the APIRO UI.
- Manually configuring a schema and feeds will give you greater control over the config and allows you to implement our advanced functions.
- Since you must have already completed
Section1 GIT via UIyou will already have aCUSTOMERschema, and you will not be allowed to create multiple schemas with the same name. - Therefore, this section refers to
SCHEMA_CUSTOMER2instead ofSCHEMA_CUSTOMERbecause every entity must be unique. In this section we will create a second schema called CUSTOMER2. - We will walk through how to manually create the CUSTOMER2 schema and
CUSTOMERS_A_XLSX2feed. -
In order to achieve this we can use any IDE, but we recommend using Intellij and placing this apirov1root.xsd file into your project root directory.
Description Config Reference Artifacts Required prerequisites
Developing Config Manually
Manually generate the SCHEMA_CUSTOMER2.xml config file
- Place the XSD file to the root directory of your project in Intellij, this XSD file apirov1root.xsd which will validate all configuration files.
-
Create a file SCHEMA_CUSTOMER2.xml, copy the contents below and paste them in the new file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <loadOrder>15</loadOrder> <schemas> <schema defBacked="false" historical="false" name="[SCHEMA_NAME]"> <groupTags> <groupTag>[MY_SCHEMA_GROUP]</groupTag> </groupTags> <identityKeys> <identityKey>[IDENTITY_KEY]</identityKey> </identityKeys> <dataPoints> <dataPoint name="[NAME]" displayName="[DISPLAY_NAME]" dataType="[DATA_TYPE]"> <nullable>false</nullable> </dataPoint> </dataPoints> </schema> </schemas> </apiroConf> -
Note: It is highly recommended to follow the Best practices guide when saving the new file. For example, start every schema file name with
SCHEMA_and every feed file name withFEED_. Schema configs should be copied into aschemasdirectory and all feed configs should be copied into adataFeedsdirectory. - However, the directory structure will not affect the application since all configuration files are loaded recursively and the names of the files are ignorred.
- Replace
[SCHEMA_NAME]withCUSTOMER2and add the identity key,BACdireclty under the<schema>element as shown below. You can provide a list of identity keys and they will be used to uniquely identify a data block (ie. data record). - Replace [MY_SCHEMA_GROUP] with SANDBOX.
- Replace the data point
[NAME]withBAC,[DISPLAY_NAME]withBank Access Codeand[DATA_TYPE]withSTRING. -
Mark the
BACdata point as<nullable>false</nullable>as shown below and you are ready to pushSCHEMA_CUSTOMER2.xmltoGIT.NOTE: Ensure the identity key is always set to non-nullable. If the identity key is not configured as
false , Apiro will not deploy the CUSTOMER schema into the Apiro engine. This behavior is by design to ensure data integrity.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
- Add all remaining data points as shown below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <loadOrder>15</loadOrder> <schemas> <schema defBacked="false" historical="false" name="CUSTOMER2"> <groupTags> <groupTag>SANDBOX</groupTag> </groupTags> <identityKeys> <identityKey>BAC</identityKey> </identityKeys> <dataPoints> <dataPoint name="BAC" displayName="Bank Access Code" dataType="STRING"> <nullable>false</nullable> </dataPoint> <dataPoint displayName="First Name" name="FIRST_NAME" dataType="STRING" > </dataPoint> <dataPoint displayName="Last Name" name="LAST_NAME" dataType="STRING" > </dataPoint> <dataPoint displayName="Address" name="ADDRESS" dataType="STRING" > </dataPoint> <dataPoint displayName="Phone Number" name="PHONE_NUMBER" dataType="STRING" > </dataPoint> <dataPoint displayName="Age" name="AGE" dataType="INTEGER" > </dataPoint> <dataPoint displayName="Yearly Income" name="YEARLY_INCOME" dataType="DECIMAL" > </dataPoint> <dataPoint displayName="Tax File Number" name="TFN" dataType="STRING" > </dataPoint> <dataPoint displayName="Investment Portfolio Value" name="PORTFOLIO_VALUE" dataType="DECIMAL" > </dataPoint> <dataPoint displayName="Company Name" name="COMPANY_NAME" dataType="STRING" > </dataPoint> <dataPoint displayName="Company Address" name="COMPANY_ADDRESS" dataType="STRING" > </dataPoint> <dataPoint displayName="XML Root Doc" name="xmlRootDoc" dataType="XML" > </dataPoint> <dataPoint displayName="JSON Root Doc" name="jsonRootDoc" dataType="JSON" > </dataPoint> <dataPoint displayName="Profile Image" name="PROFILE_IMAGE" dataType="BLOB" > </dataPoint> </dataPoints> </schema> </schemas> </apiroConf>
Manually generate config the config file FEED_CUSTOMER_GIT_XLSX2.xml feed
- Create a file called
FEED_CUSTOMERS_A_XLSX2.xml -
Copy the contents below and paste them in the newly created file as shown below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
<?xml version="1.0" encoding="UTF-8"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <loadOrder>30</loadOrder> <dataFeeds> <dataFeed definition="[FEED_DEFINITION]" name="[FEED_NAME]"> <execPriority>50</execPriority> <enabled>true</enabled> <push>false</push> <pull>true</pull> <schema>[SCHEMA_NAME]</schema> <config> <![CDATA[{ "dataSource" : { "entity" : "[FEED_SOURCE_ENTITY]", "config" : { [FEED_SOURCE_CONFIGURATION] } }, "itemLimit" : [ITEM_LIMIT], "titleAtLine": [TITLE_AT_LINE],//// Only needed for a CSV. Do not use for a Spreadsheet. "dataAtLine": [DATA_AT_LINE], "sheet": [SPREADSHEET_SHEET], "explicitMappings" : [ { "dictionary" : "[NAME]", "value" : "#GRV{PAYLOAD.resolve('[PAYLOAD_PATH]')}" }, { "dictionary" : "[NAME]", "value" : "#GRV{PAYLOAD.resolve('[PAYLOAD_PATH]')}" }, ] } ]]> </config> </dataFeed> </dataFeeds> </apiroConf> -
Replace
name="[FEED_NAME]"withCUSTOMERS_A_XLSX2 - Replace
<schema>[SCHEMA_NAME]</schema>withCUSTOMER2to associate this feed with CUSTOMER2 schema. - There is one to many relationship from Schema to Feeds.
-
Replace
[FEED_DEFINITION]withEXPR_EXCEL_FEED2because we will be sourcing an Excel file.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
<?xml version="1.0" encoding="UTF-8"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <loadOrder>20</loadOrder> <dataFeeds> <dataFeed definition="EXPR_EXCEL_FEED2" name="CUSTOMERS_A_XLSX2"> <execPriority>50</execPriority> <enabled>true</enabled> <push>false</push> <pull>true</pull> <schema>CUSTOMER2</schema> <config><![CDATA[{ "dataSource" : { "entity" : "[FEED_SOURCE_ENTITY]", "config" : { [FEED_SOURCE_CONFIGURATION] } }, "itemLimit" : [ITEM_LIMIT], "titleAtLine": [TITLE_AT_LINE],// Only needed for a CSV. Do not use for a Spreadsheet. "dataAtLine": [DATA_AT_LINE], "sheet": [SPREADSHEET_SHEET], "explicitMappings" : [ { "dictionary" : "[NAME]", "value" : "#GRV{PAYLOAD.resolve('[PAYLOAD_PATH]')}" }, { "dictionary" : "[NAME]", "value" : "#GRV{PAYLOAD.resolve('[PAYLOAD_PATH]')}" }, ] } ]]></config> </dataFeed> </dataFeeds> </apiroConf> -
Replace the template dataSource with this one
1 2 3 4 5 6 7 8 9 10
"dataSource" : { "entity" : "GIT", "config" : { "username" : "${SYS:APIRO_GITHUB_USERNAME}", "password" : "${SYS:APIRO_GITHUB_PW}", "gitURL": "https://github.com/redapiro/apiro_examples.git", "branch" : "main", "pathPrefix": "/artifacts/source_files/customers_a.xlsx" } }, -
See below how the feed config for
CUSTOMERS_A_XLSX2will look after the data source replacement.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
<?xml version="1.0" encoding="UTF-8"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <loadOrder>20</loadOrder> <dataFeeds> <dataFeed definition="EXPR_EXCEL_FEED2" name="CUSTOMERS_A_XLSX2"> <execPriority>50</execPriority> <enabled>true</enabled> <push>false</push> <pull>true</pull> <schema>CUSTOMER2</schema> <config><![CDATA[{ "dataSource" : { "entity" : "GIT", "config" : { "username" : "${SYS:APIRO_GITHUB_USERNAME}", "password" : "${SYS:APIRO_GITHUB_PW}", "gitURL": "https://github.com/redapiro/apiro_examples.git", "branch" : "main", "pathPrefix": "/artifacts/source_files/customers_a.xlsx" } }, "itemLimit" : 10, "dataAtLine": 2, //This specifies the excel spreadsheet's row where the first data line starts. "sheet": "data", "explicitMappings" : [ { "dictionary" : "[NAME]", "value" : "#GRV{PAYLOAD.resolve('[PAYLOAD_PATH]')}" }, { "dictionary" : "[NAME]", "value" : "#GRV{PAYLOAD.resolve('[PAYLOAD_PATH]')}" }, ] } ]]></config> </dataFeed> </dataFeeds> </apiroConf> -
Specify item
"itemLimit" : 10,. This means it will only ingest the top 10 data rows from the excel spreadsheet. If this setting is ommitted then all the rows will be sourced. - Replace the placeholder
itemLimit, titleAtLine, dataAtLine and sheetwith the followingRefer to the Data Feeds configuration reference for details of these settings1 2 3 4
"itemLimit":10, "titleAtLine": 1, //This specifies the CSV'ss row that contains the columns name to use for creating Data Dictionary names. Do not use if you are sourcing a spreadsheet. "dataAtLine": 2, //This specifies the excel spreadsheet's row where the first data line starts. "sheet": "data", //This specifies the excel spreasheet's sheet name we want to source from. If this setting is ommitted the default value is 'Sheet1' -
Below is the resulting file:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
<?xml version="1.0" encoding="UTF-8"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <loadOrder>20</loadOrder> <dataFeeds> <dataFeed definition="EXPR_EXCEL_FEED2" name="CUSTOMERS_A_XLSX2"> <execPriority>50</execPriority> <enabled>true</enabled> <push>false</push> <pull>true</pull> <schema>CUSTOMER2</schema> <config> <![CDATA[{ "dataSource" : { "entity" : "GIT", "config" : { "username" : "${SYS:APIRO_GITHUB_USERNAME}", "password" : "${SYS:APIRO_GITHUB_PW}", "gitURL": "https://github.com/redapiro/apiro_examples.git", "branch" : "main", "pathPrefix": "/artifacts/source_files/customers_a.xlsx" } }, "itemLimit" : 10, "titleAtLine": 1, "dataAtLine": 3, "sheet": "data", "explicitMappings" : [ { "dictionary" : "[NAME]", "value" : "#GRV{PAYLOAD.resolve('[PAYLOAD_PATH]')}" }, { "dictionary" : "[NAME]", "value" : "#GRV{PAYLOAD.resolve('[PAYLOAD_PATH]')}" }, ] } ]]> </config> </dataFeed> </dataFeeds> </apiroConf> -
Complete the mapping of the excel columns with the Data Point descriptors specified in the
CUSTOMER2schema. - The data point descriptors are the ones specified in the
CUSTOMER2schema asdataPoints. - For example, BAC, FIRST_NAME, LAST_NAME, ADDRESS, PHONE_NUMBER, AGE, YEARLY_INCOME, TFN, PORTFOLIO_VALUE etc.
- The mapping is achieved by using a Groovy script to resolve the Excel spreadsheet column positions, eg.
"value" : "#GRV{PAYLOAD.resolve('B')}", to the specific data point descriptor eg."dictionary" : "FIRST_NAME"as shown in the completed configCUSTOMERS_A_XLSX2below. - If the file we are sourcing was a CSV file then the Groovy script would have specified a column name.
- If the file we are sourcing was an XML file then the Groovy script would have specified an XML path.
- If the file we are sourcing was a JSON file then the Groovy script would have specified a JSON path.
- Refer to Data Feeds - Configuration Reference for more details.
- Replace the
"explicitMappings:[]"with the following data mappings1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
"explicitMappings": [ { "dictionary": "BAC", "value": "#GRV{PAYLOAD.resolve('A')}" }, { "dictionary": "FIRST_NAME", "value": "#GRV{PAYLOAD.resolve('B')}" }, { "dictionary": "LAST_NAME", "value": "#GRV{PAYLOAD.resolve('C')}" }, { "dictionary": "ADDRESS", "value": "#GRV{PAYLOAD.resolve('D')}" }, { "dictionary": "PHONE_NUBER", "value": "#GRV{PAYLOAD.resolve('E')}" }, { "dictionary": "AGE", "value": "#GRV{PAYLOAD.resolve('F')}" }, { "dictionary": "YEARLY_INCOME", "value": "#GRV{PAYLOAD.resolve('G')}" }, { "dictionary": "TFN", "value": "#GRV{PAYLOAD.resolve('H')}" }, { "dictionary": "PORTFOLIO_VALUE", "value": "#GRV{PAYLOAD.resolve('I')}" }, { "dictionary": "COMPANY_NAME", "value": "#GRV{PAYLOAD.resolve('J')}" }, { "dictionary": "COMPANY_ADDRESS", "value": "#GRV{PAYLOAD.resolve('K')}" }, { "dictionary": "COMPANY_WEBSITE", "value": "#GRV{PAYLOAD.resolve('L')}" }, { "dictionary": "PROFILE_IMAGE", "value": "#GRV{PAYLOAD.resolve('M')}" }, { "dictionary": "XML_ROOT_DOC", "value": "#GRV{PAYLOAD.resolve('N')}" }, { "dictionary": "JSON_ROOT_DOC", "value": "#GRV{PAYLOAD.resolve('O')}" } ] - The resulting file can be seen below
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85
<?xml version="1.0" encoding="UTF-8"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <loadOrder>20</loadOrder> <dataFeeds> <dataFeed definition="EXPR_EXCEL_FEED2" name="CUSTOMERS_A_XLSX2"> <execPriority>50</execPriority> <enabled>true</enabled> <push>false</push> <pull>true</pull> <schema>CUSTOMER2</schema> <config> <![CDATA[{ "dataSource" : { "entity" : "GIT", "config" : { "username" : "${SYS:APIRO_GITHUB_USERNAME}", "password" : "${SYS:APIRO_GITHUB_PW}", "gitURL": "https://github.com/redapiro/apiro_examples.git", "branch" : "main", "pathPrefix": "/artifacts/source_files/customers_a.xlsx" } }, "itemLimit" : 10, "dataAtLine": 3, "sheet": "data", "explicitMappings" : [ { "dictionary" : "BAC", "value" : "#GRV{PAYLOAD.resolve('A')}" }, { "dictionary" : "FIRST_NAME", "value" : "#GRV{PAYLOAD.resolve('B')}" }, { "dictionary" : "LAST_NAME", "value" : "#GRV{PAYLOAD.resolve('C')}" }, { "dictionary" : "ADDRESS", "value" : "#GRV{PAYLOAD.resolve('D')}" }, { "dictionary" : "PHONE_NUMBER", "value" : "#GRV{PAYLOAD.resolve('E')}" }, { "dictionary" : "AGE", "value" : "#GRV{PAYLOAD.resolve('F')}" }, { "dictionary" : "YEARLY_INCOME", "value" : "#GRV{PAYLOAD.resolve('G')}" }, { "dictionary" : "TFN", "value" : "#GRV{PAYLOAD.resolve('H')}" }, { "dictionary" : "PORTFOLIO_VALUE", "value" : "#GRV{PAYLOAD.resolve('I')}" }, { "dictionary" : "COMPANY_NAME", "value" : "#GRV{PAYLOAD.resolve('J')}" }, { "dictionary" : "COMPANY_ADDRESS", "value" : "#GRV{PAYLOAD.resolve('K')}" }, { "dictionary" : "COMPANY_WEBSITE", "value" : "#GRV{PAYLOAD.resolve('L')}" }, { "dictionary" : "PROFILE_IMAGE", "value" : "#GRV{PAYLOAD.resolve('M')}" } ] } ]]> </config> </dataFeed> </dataFeeds> </apiroConf>
New configuration files deployment
- Push the config files you just created (
SCHEMA_CUSTOMER2.xmlandFEED_CUSTOMERS_A_XLSX2.xml), to the GIT repository you configured with your Apiro instance. - Then, follow the guide below to deploy the newly created configuration files.
-
Once the files are pushed and reloaded you will be able to see the new schema and feed under
SANDBOXgroup.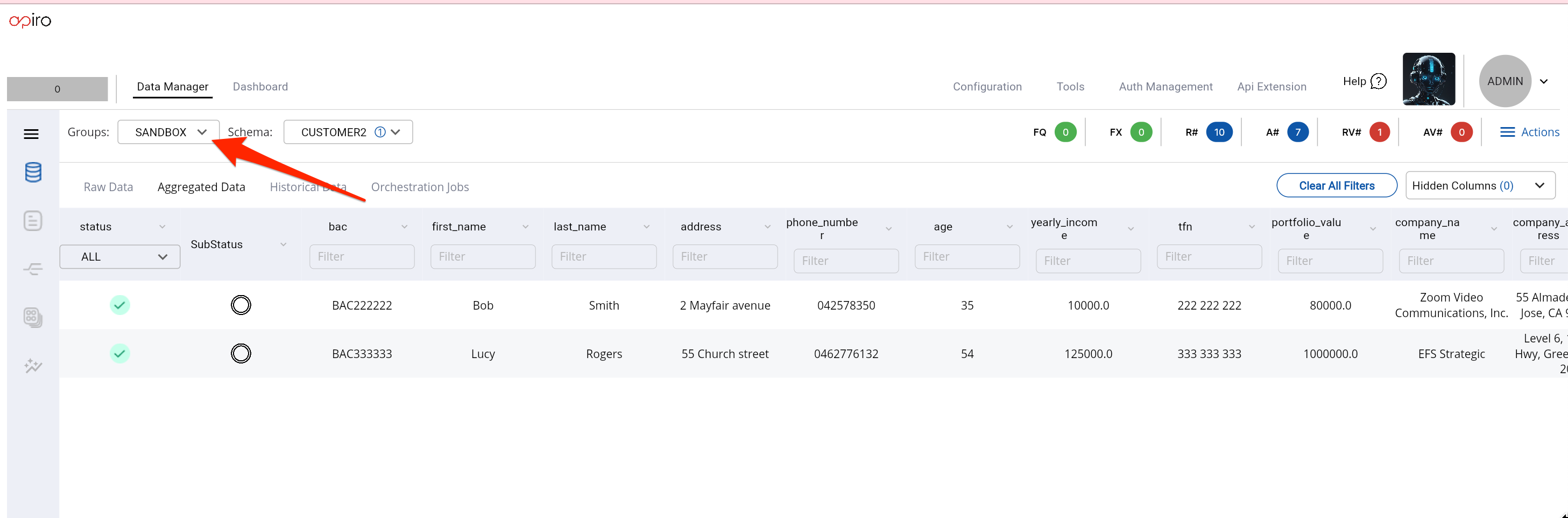
Deploy config files
Follow these steps Config Deployment to deploy and start using your configuration files.
Common Mistakes
- Within every schema, ensure that an
identity keyis defined. Always ensure the identity key is set to nullable = false. If an identity key is not set to nullable = false then Apiro will invalidate the schema and will cause a bootconf error in logs. - There are times that your source file will have more data lines that what is actually sourced. In the event this happens please have a look at the properties
dataAtLinewhich specifies the first datablock in the file anditemLimitwhich specifies the maximum number of datablock to source. If you do not specifyitemLimitthen there is no limit.