Section 4 - Create Raw Validators using IntelliJ
Go back to Getting started guide
In this section we will:
- create a NOT NULL raw validator
- create a POSITIVE raw validator
-
create a IN_SET raw validator
Description Config Reference Artifacts
Processing Pipeline
Raw Validators without configurations
- Raw validators are part of the processing pipeline of each data point.
- They are defined in the config schemas. In this case CUSTOMER schema.
- We start by opening the
SCHEMA_CUSTOMERS.xmlfile we created in the previous section, in IntelliJ. Note: This file is used a starting point just before starting section 4, to add data validators and processors. If you were not able to complete the previous section you could copy the configuration below and paste it intoSCHEMA_CUSTOMERS.xmlto continue with this section. - We will now implement raw validations for the data descriptor
AGEhighligted below at line 45.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70
<?xml version="1.0" encoding="UTF-8"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <groups/> <loadOrder>15</loadOrder> <schemas> <schema defBacked="false" historical="false" name="CUSTOMER"> <groupTags> <groupTag>EXAMPLES</groupTag> </groupTags> <metaData/> <identityKeys> <identityKey>BAC</identityKey> </identityKeys> <!-- Data Point descriptions --> <dataPoints> <dataPoint name="BAC" dataType="STRING" canEditValid="true" canEditViolated="true" displayName="BAC"> <nullable>false</nullable> <metaData> <item name="piiClassification"> <simpleValues> <simpleValue>High Risk</simpleValue> </simpleValues> </item> </metaData> <!-- BAC data point processors --> <rawDPValidators/> <rawDPProcessors/> <!--consolidationAlgorithm></consolidationAlgorithm --> <consDPValidators/> <consDPProcessors/> </dataPoint> <dataPoint name="FIRST_NAME" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="FIRST NAME"/> <dataPoint name="LAST_NAME" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="LAST NAME"/> <dataPoint name="ADDRESS" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="ADDRESS"/> <dataPoint name="PHONE_NUMBER" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PHONE NUMBER"/> <dataPoint name="AGE" canEditValid="false" canEditViolated="true" dataType="INTEGER" displayName="AGE"/> <dataPoint name="YEARLY_INCOME" canEditValid="false" canEditViolated="true" dataType="DECIMAL" displayName="YEARLY INCOME"/> <dataPoint name="TFN" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="TFN"/> <dataPoint name="PORTFOLIO_VALUE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PORTFOLIO VALUE"/> <dataPoint name="COMPANY_NAME" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY NAME"/> <dataPoint name="COMPANY_ADDRESS" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY ADDRESS"/> <dataPoint name="PROFILE_IMAGE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PROFILE_IMAGE"/> <dataPoint name="COMPANY_WEBSITE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY WEBSITE"/> <dataPoint name="XML_ROOT_DOC" canEditValid="false" canEditViolated="true" displayName="XML Root Doc" dataType="XML"/> <dataPoint name="JSON_ROOT_DOC" canEditValid="false" canEditViolated="true" displayName="JSON Root Doc" dataType="JSON"/> </dataPoints> <schemaAppliedProcessors> <groupTags> <groupTag>DEFAULT</groupTag> </groupTags> <metaData/> <rawDPValidators/> <rawDPProcessors/> <consDPValidators/> <consDPProcessors/> <dataBlockProcessors/> </schemaAppliedProcessors> <alerts/> </schema> </schemas> </apiroConf> - Copy the
AGEelement below and override line 45. This will implement theNOT_NULLandPOSITIVEraw data point validators for theAGEData Point Descriptor. Note: Before proceeding, you must ensure that theAGE dataTypeisINTEGERand not aSTRING.1 2 3 4 5 6 7 8
<dataPoint name="AGE" dataType="INTEGER" canEditValid="false" canEditViolated="false" displayName="Age"> <rawDPValidators> <rawDPValidator name="INVALID_IF_NULL" entity="NOT_NULL"/> // The name can be anything and it will appear in data audit/lineage <rawDPValidator name="INVALID_IF_NEGATIVE" entity="POSITIVE"> <lateBound>false</lateBound> // This is the default value if one is not specified </rawDPValidator> </rawDPValidators> </dataPoint> - You must now push your updated
SCHEMA_CUSTOMER.xmlfile to GIT and deploy as per the instructions provided at the bottom of this page to reload the configuration. - You have just implemented a chain of Raw Validators for the
AGEdata point. - If the
AGEvalue of any data feed isNULLorNON POSITIVE, a violation will be raised, tracked, audited and shown in the UI.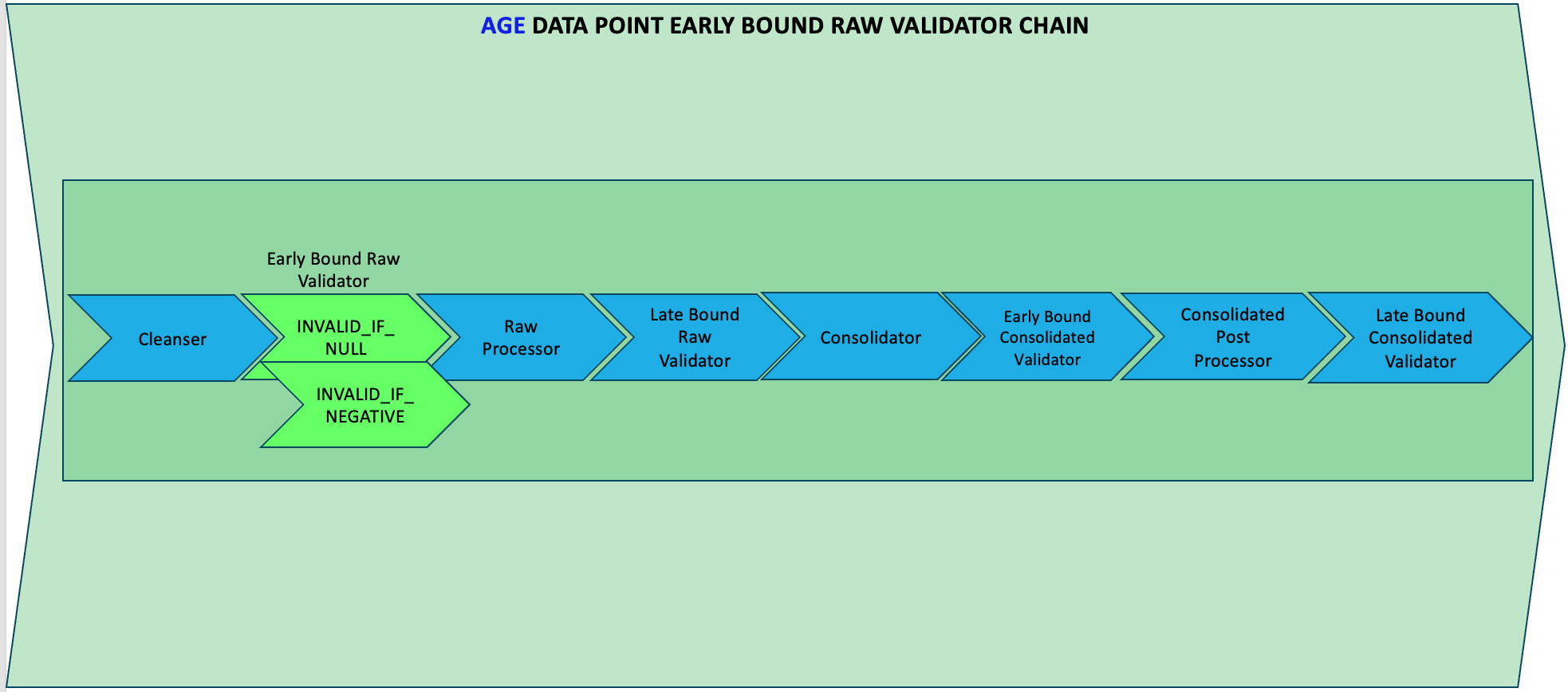
- After reloading the schema you need to trigger sourcing for both feeds individually (
CUSTOMERS_A_XLSX,CUSTOMERS_B_XLSX) to ingest the data and process each pipeline for every data point and data block.
- You can see below how the UI shows this violation in the Raw Data table
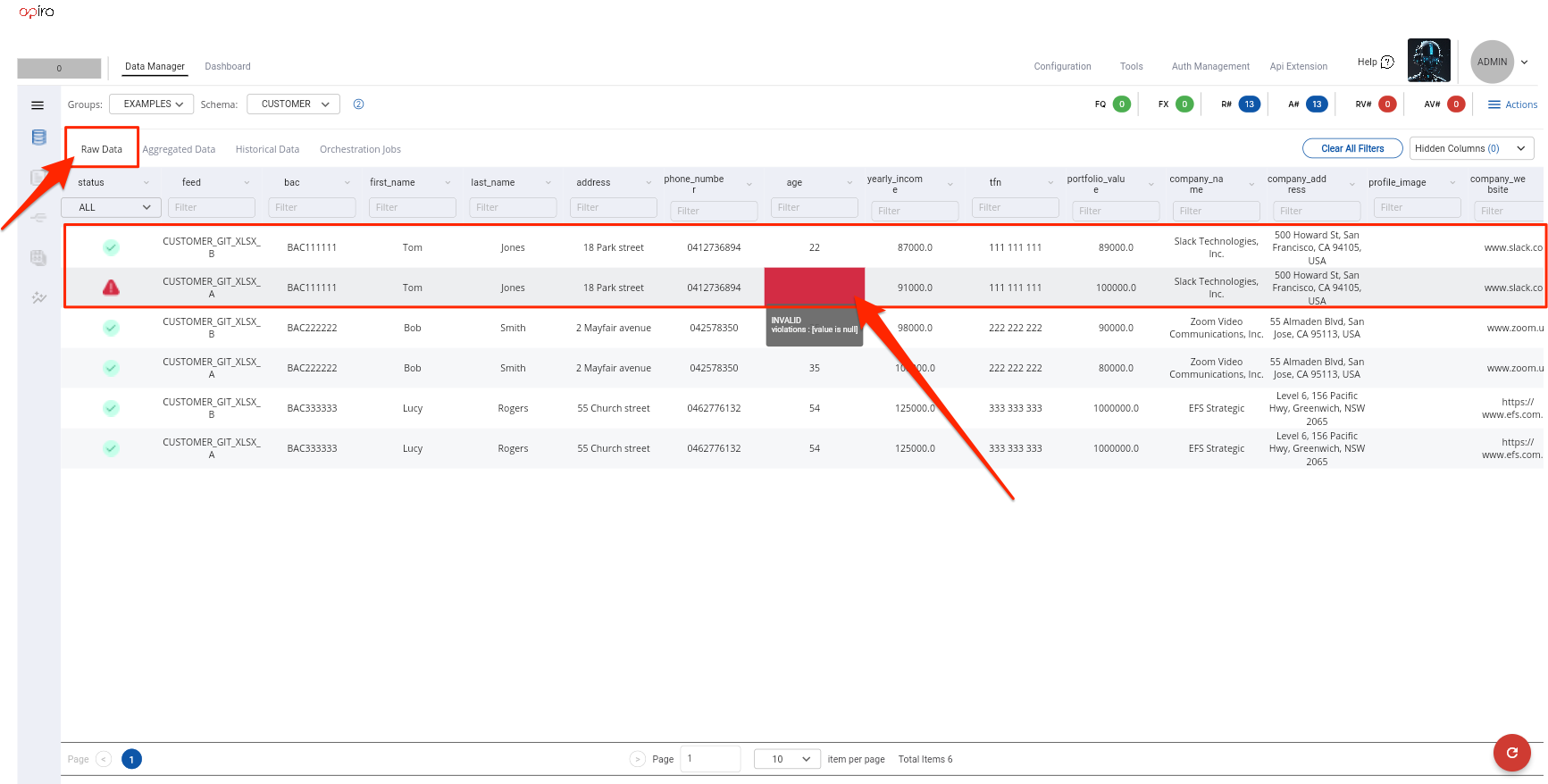
- However, the aggregated table does not show any violations because the default behaviour is to aggregate all
VALIDdata point values using the defaultmean averagealgorithm. In this case theAGEsourced from one feed wasINVALIDbecause it wasNULLand the value sourced from the second feed was22. This is why the aggregated value was 22 because there was only oneVALIDraw value. We will see later in the guide how we can customize this behaviour. For example we could specify that a data point value cannot be aggregated unless atleast 2 feeds are available. This could be as simple as configuring a<consDPValidator name="HAS_MIN_FEED_2" entity="MINIMUM_FEEDS">as shown below. Do not add this validator at the moment as it is out of the scope of this section. It will be discussed at a later section.1 2 3 4 5 6 7 8 9 10 11 12 13
<dataPoint name="AGE" dataType="STRING"> <consDPValidators> <consDPValidator name="MIN_FEEDS_FOR_AGE" entity="MINIMUM_FEEDS"> <config> <![CDATA[ { "minFeeds" : 2 } ]]> </config> </consDPValidator> </consDPValidators> </dataPoint>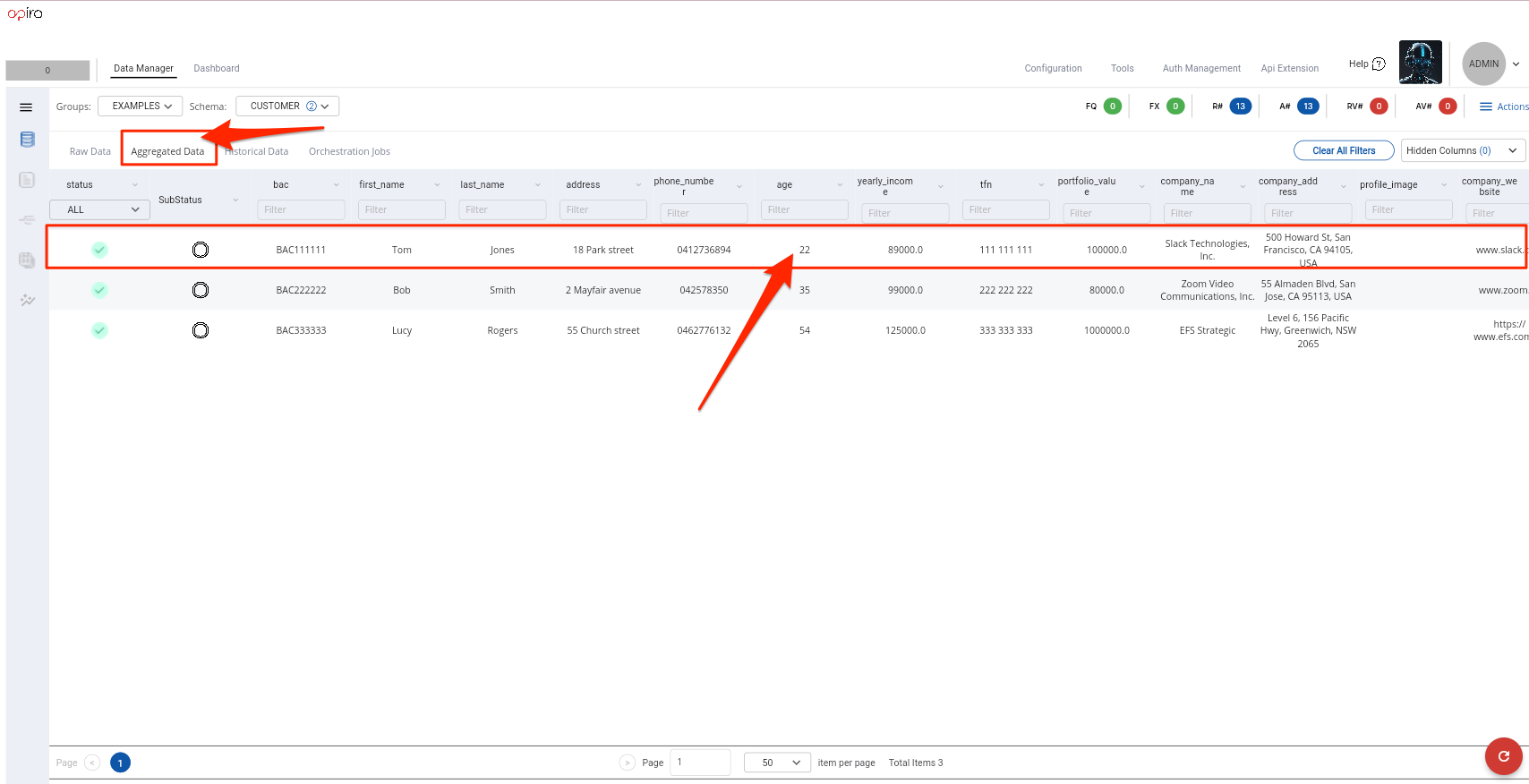
-
If we double click on the aggregated cell in this case
22we will be able to see the Data Audit/Lineage popup dialog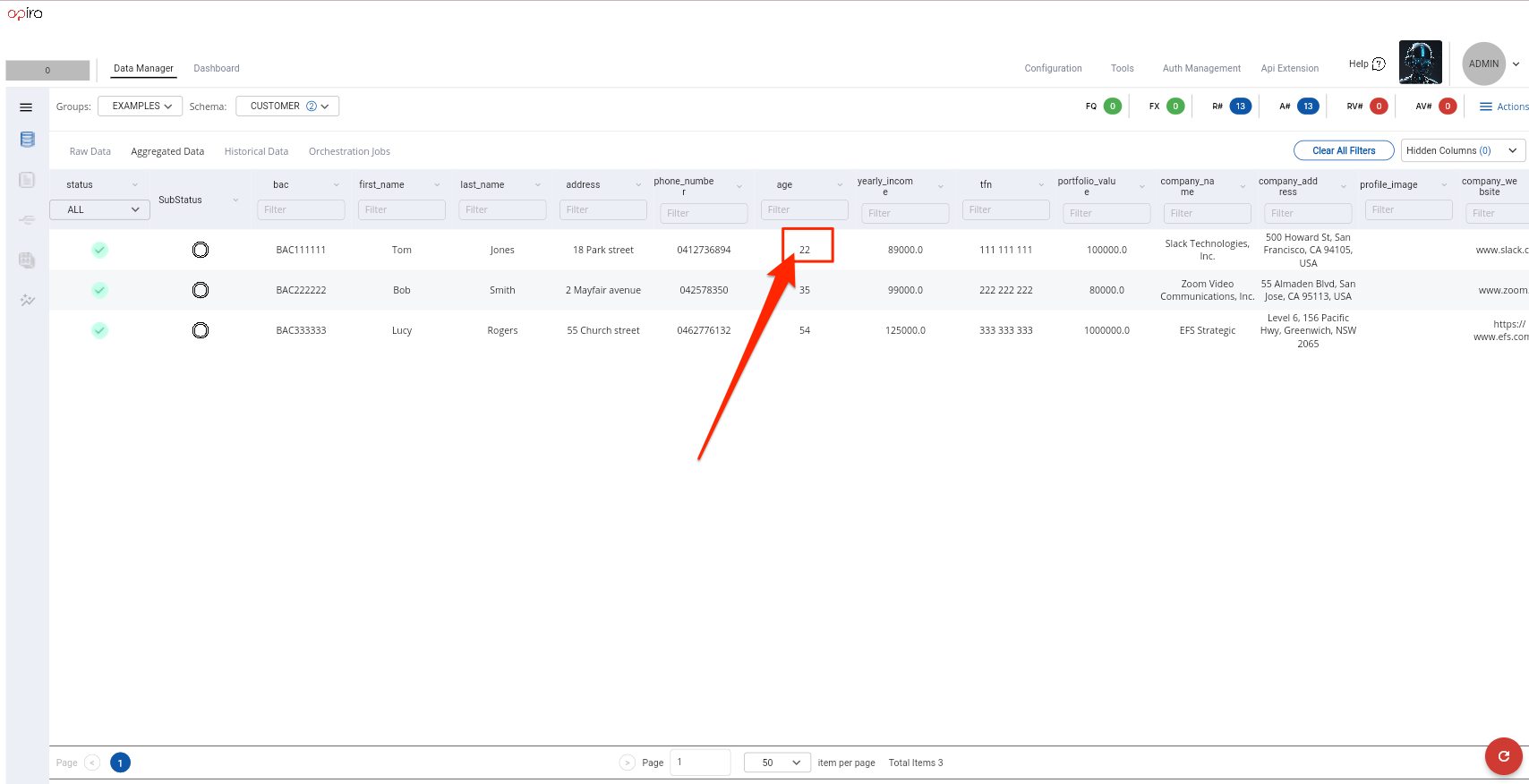
-
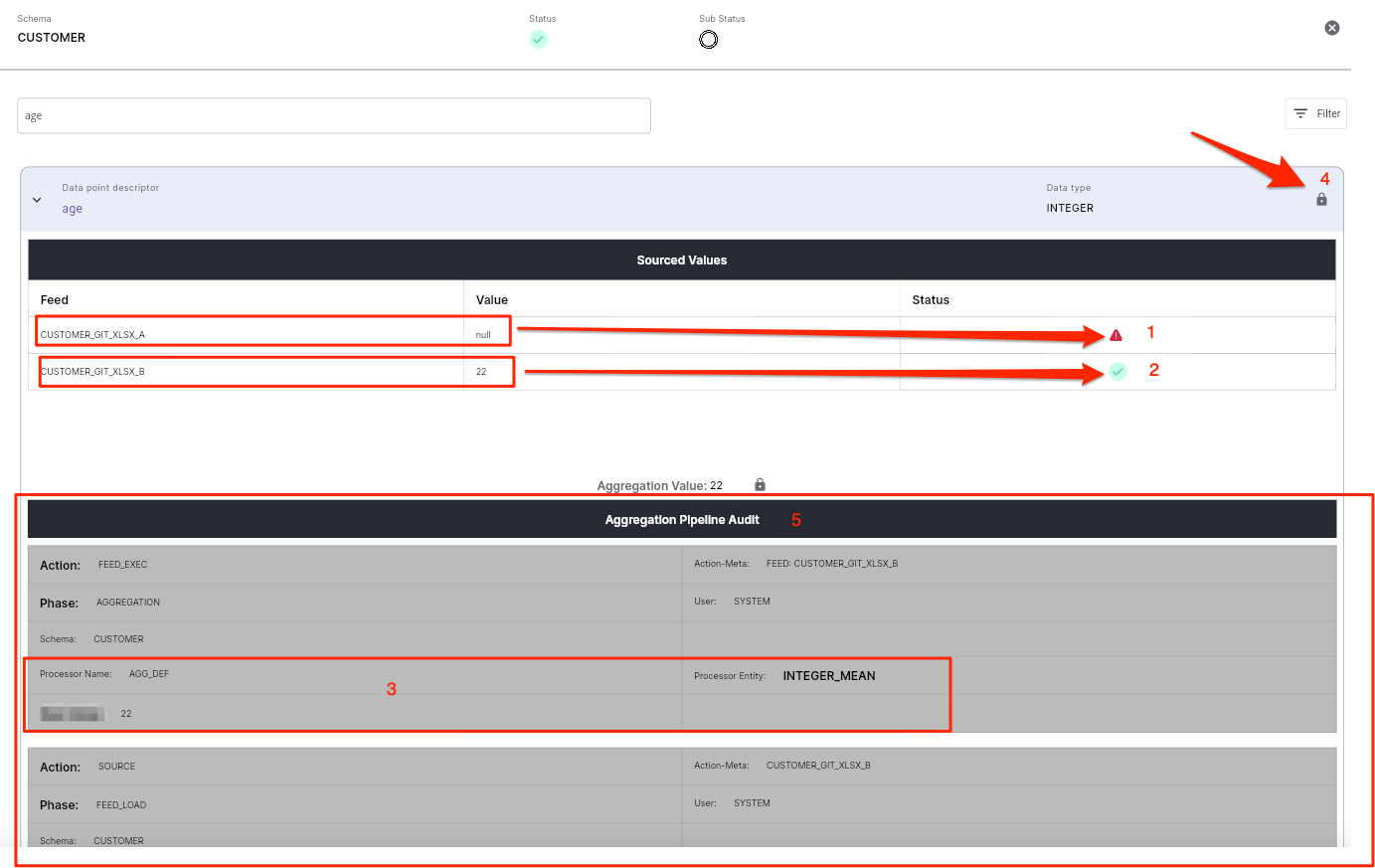
The Data Audit/Lineage popup dialog will show all the information related to this specific data point.
- (1) The name of the first feed
CUSTOMERS_A_XLSX, the sourced valuenulland theINVALIDstatus of the data point from this feed. - (2) The name of the second feed
CUSTOMERS_B_XLSX, the sourced value22and theVALIDstatus of the data point from this feed. - (3) The aggregated value and the aggregation algorithm
INTEGER_MEANused to perform the aggregation. - (4) Indicator if we are allowed to manually edit this data point value.
-
(5) A complete data processing pipeline showing how the values were changed during the process.
-
Note: Whether a data point value is manually editable or not, is specified in the schema config file as an attribute on each data point as shown below
1 2 3 4 5
<dataPoint name="AGE" displayName="Age" dataType="STRING" canEditValid="false" canEditViolated="false"/> - If
canEditViolated="true"/>and/orcanEditValid="true"/>were set to true then the UI would allow the manual updating of any values that are violated.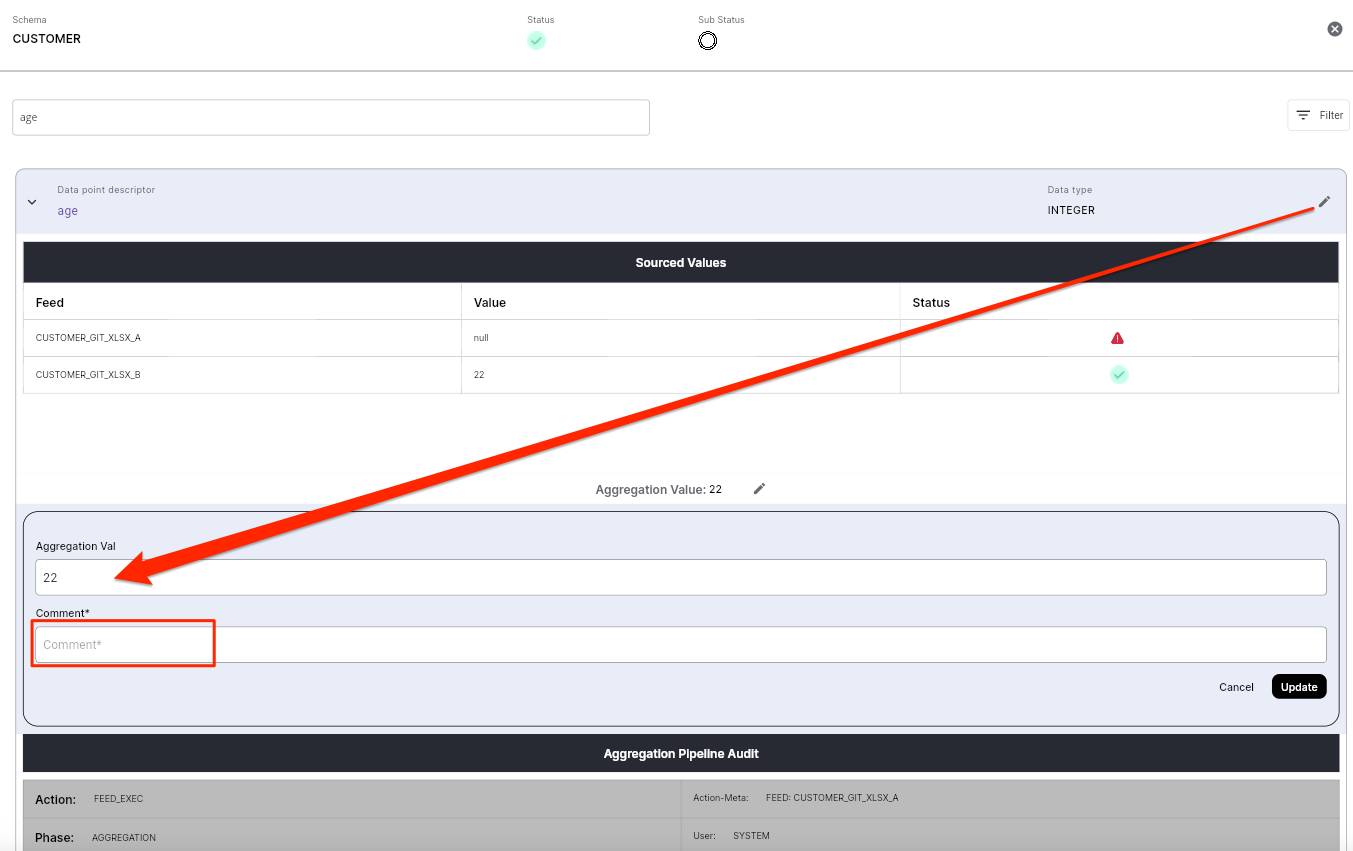
- (1) The name of the first feed
Raw Validators WITH configuration
- Now, lets have a look at the IN_SET Validator.
- This predefined validator accepts a configuration as shown below.
- It validlates the
FIRST_NAMEvalues and specifies that onlyTomorBobare valid. Any other first names will raise a violation. - Copy the
FIRST_NAMEelement below and override it in theCUSTOMER_SCHEMA.xmlfile. - Push to GIT and reload the config as described at the bottom of this page.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
<dataPoint name="FIRST_NAME" dataType="STRING" displayName="First Name" canEditValid="true" canEditViolated="true"> <rawDPValidators> <rawDPValidator name="IN_BAC_SET_CHECK " entity="IN_SET"> <config> <![CDATA[ { ignoreCase : true, options : [ "Tom", "Bob"] } ]]> </config> </rawDPValidator> </rawDPValidators> </dataPoint> - You need to retrigger sourcing as we described above.
- As shown in the screenshot below the record with first name
Lucyare raised as violated fields. -
We will see later in the guide that this
exclusionlist doesn't always have to be hard coded in the config. It can be dynamically retrieved by external service or another schema.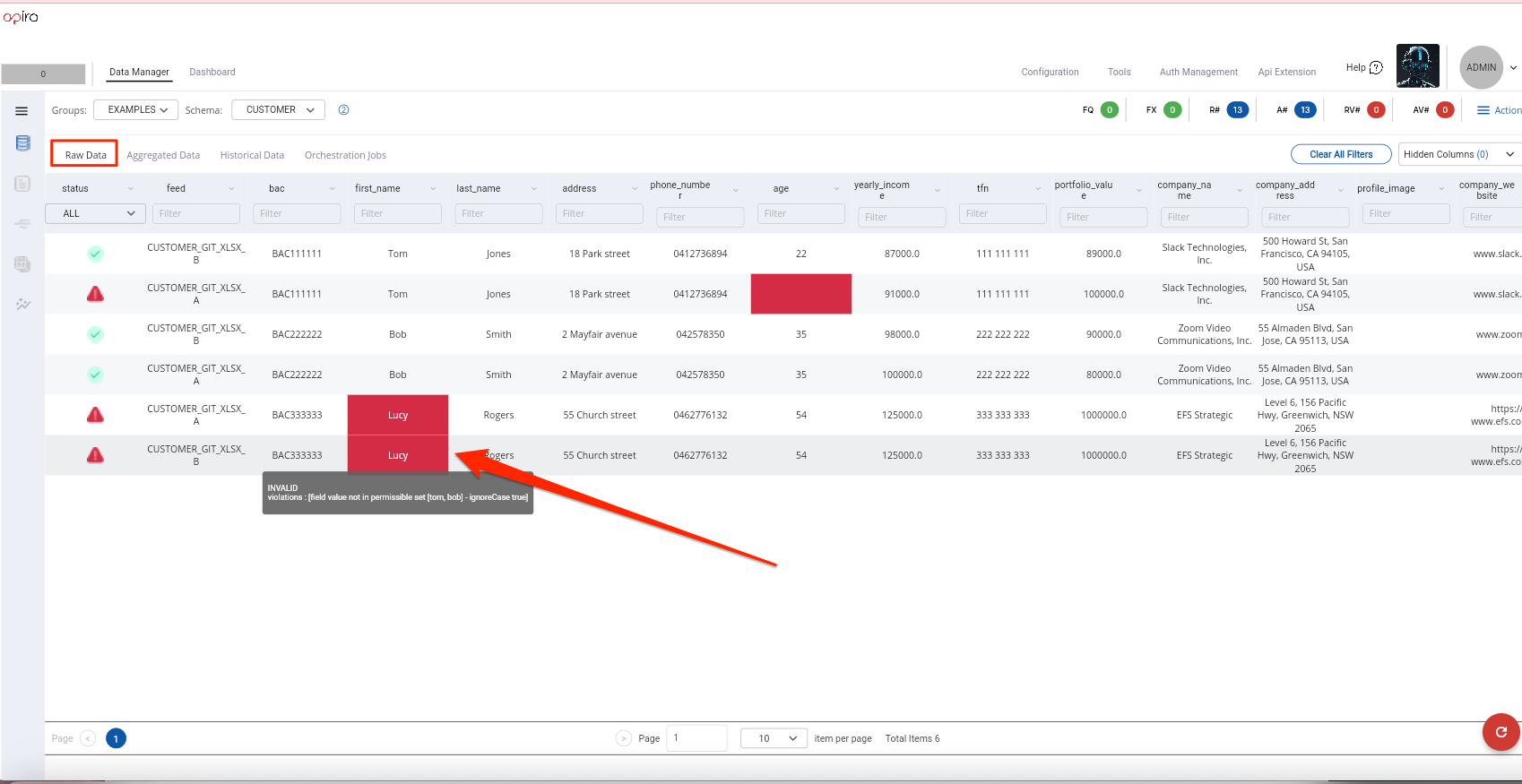
-
As mentioned previously Apiro provides a fine-grained control as to how
rawandconsolidated/aggregateddata is processed and validated. - We can see below that because the raw data for first name was violated, then pipeline did not proceed with consolidating the data points related to
FIRST_NAME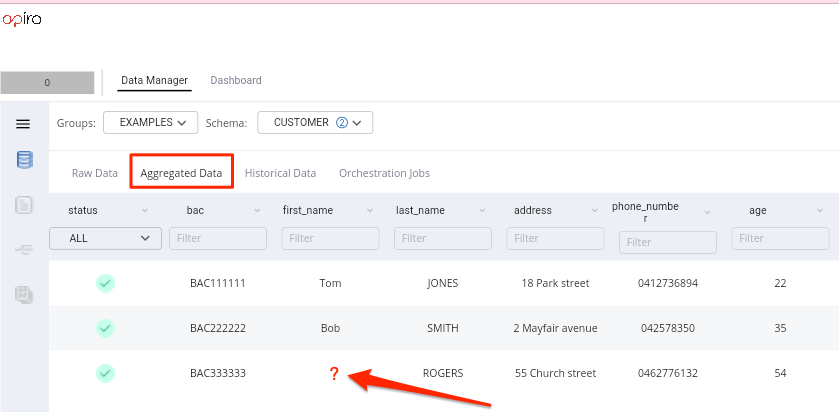
- You will also notice that there was no violation flagged for consolidated data even thought the value is missing.
- In order to flag this violation we need to in introduce a
</consDPValidator> - We will discuss consolidate data point validators later in the guide but we are provide this here for completeness
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
- Once we add the consolidated data point validator for
FIRST_NAMEwe can see the violation raised.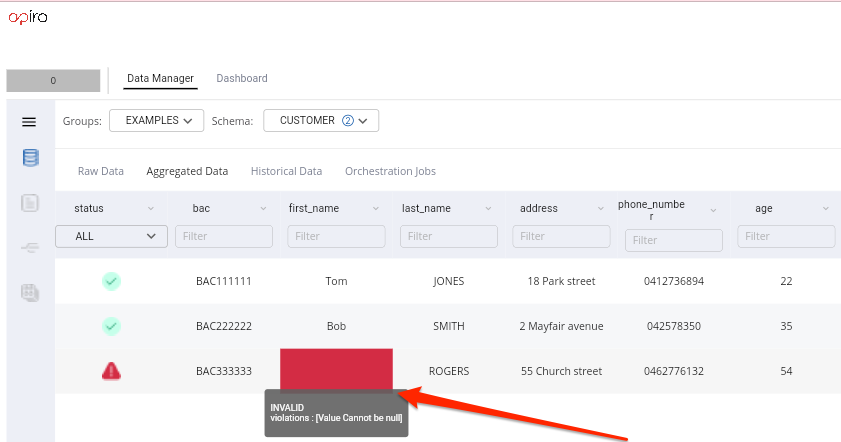
Bringing it all together
Completed configuration files
- This is the completed CUSTOMER schema configuration file that implements all the above. Notice how simple and quick it was to add out of the box and custom validators in a single configuration using the existing pre wired pipelines, audit and data lineage features.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
<?xml version="1.0" encoding="UTF-8"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <groups/> <loadOrder>15</loadOrder> <schemas> <schema defBacked="false" historical="false" name="CUSTOMER"> <groupTags> <groupTag>EXAMPLES</groupTag> </groupTags> <metaData/> <identityKeys> <identityKey>BAC</identityKey> </identityKeys> <!-- Data Point descriptions --> <dataPoints> <dataPoint name="BAC" dataType="STRING" canEditValid="true" canEditViolated="true" displayName="BAC"> <nullable>false</nullable> <metaData> <item name="piiClassification"> <simpleValues> <simpleValue>High Risk</simpleValue> </simpleValues> </item> </metaData> <!-- BAC data point processors --> <rawDPValidators/> <rawDPProcessors/> <!--consolidationAlgorithm></consolidationAlgorithm --> <consDPValidators/> <consDPProcessors/> </dataPoint> <dataPoint name="FIRST_NAME" dataType="STRING" displayName="First Name" canEditValid="true" canEditViolated="true"> <rawDPValidators> <rawDPValidator name="IN_BAC_SET_CHECK " entity="IN_SET"> <config> <![CDATA[ { ignoreCase : true, options : [ "Tom", "Bob"] } ]]> </config> </rawDPValidator> </rawDPValidators> <consDPValidators> <consDPValidator name="INVALID_IF_CONSOLIDATED_NULL" entity="NOT_NULL"/> </consDPValidators> </dataPoint> <dataPoint name="LAST_NAME" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="LAST NAME"/> <dataPoint name="ADDRESS" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="ADDRESS"/> <dataPoint name="PHONE_NUMBER" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PHONE NUMBER"/> <dataPoint name="AGE" dataType="INTEGER" canEditValid="true" canEditViolated="true" displayName="Age"> <rawDPValidators> <rawDPValidator name="INVALID_IF_NULL" entity="NOT_NULL"/> // The name can be anything and it will appear in data audit/lineage <rawDPValidator name="INVALID_IF_NEGATIVE" entity="POSITIVE"> <lateBound>false</lateBound> // This is the default value if one is not specified </rawDPValidator> </rawDPValidators> </dataPoint> <dataPoint name="YEARLY_INCOME" canEditValid="false" canEditViolated="true" dataType="DECIMAL" displayName="YEARLY INCOME"/> <dataPoint name="TFN" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="TFN"/> <dataPoint name="PORTFOLIO_VALUE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PORTFOLIO VALUE"/> <dataPoint name="COMPANY_NAME" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY NAME"/> <dataPoint name="COMPANY_ADDRESS" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY ADDRESS"/> <dataPoint name="PROFILE_IMAGE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PROFILE_IMAGE"/> <dataPoint name="COMPANY_WEBSITE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY WEBSITE"/> <dataPoint name="XML_ROOT_DOC" canEditValid="false" canEditViolated="true" displayName="XML Root Doc" dataType="XML"/> <dataPoint name="JSON_ROOT_DOC" canEditValid="false" canEditViolated="true" displayName="JSON Root Doc" dataType="JSON"/> </dataPoints> <schemaAppliedProcessors> <groupTags> <groupTag>DEFAULT</groupTag> </groupTags> <metaData/> <rawDPValidators/> <rawDPProcessors/> <consDPValidators/> <consDPProcessors/> <dataBlockProcessors/> </schemaAppliedProcessors> <alerts/> </schema> </schemas> </apiroConf>
Deploy config files
- Follow these steps Config Deployment to deploy and start using your configuration files.