Section 5 - Create Consolidation Algorithms (aka Consolidators) using IntelliJ
Go back to Getting started guide
In this section we will:
-
show how to use a default Consolidation Algorithm
Description Config Reference Artifacts
Processing Pipeline
Data Consolidation Algorithms
- Consolidation Algoritms are part of the processing pipeline of each data point.
- They are defined in schema configurations, in this case
CUSTOMERschema. - We start by opening the
SCHEMA_CUSTOMER.xmlfile we created in the previous section, in IntelliJ. Note: This file is used a starting point just before starting section 5, to add data consolidators. -
If you were not able to complete the previous section you could copy the configuration below and paste it into
SCHEMA_CUSTOMER.xmlto continue with this section.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
<?xml version="1.0" encoding="UTF-8"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <groups/> <loadOrder>15</loadOrder> <schemas> <schema defBacked="false" historical="false" name="CUSTOMER"> <groupTags> <groupTag>EXAMPLES</groupTag> </groupTags> <metaData/> <identityKeys> <identityKey>BAC</identityKey> </identityKeys> <!-- Data Point descriptions --> <dataPoints> <dataPoint name="BAC" dataType="STRING" canEditValid="true" canEditViolated="true" displayName="BAC"> <nullable>false</nullable> <metaData> <item name="piiClassification"> <simpleValues> <simpleValue>High Risk</simpleValue> </simpleValues> </item> </metaData> <!-- BAC data point processors --> <rawDPValidators/> <rawDPProcessors/> <!--consolidationAlgorithm></consolidationAlgorithm --> <consDPValidators/> <consDPProcessors/> </dataPoint> <dataPoint name="FIRST_NAME" dataType="STRING" displayName="First Name" canEditValid="true" canEditViolated="true"> <rawDPValidators> <rawDPValidator name="IN_BAC_SET_CHECK " entity="IN_SET"> <config> <![CDATA[ { ignoreCase : true, options : [ "Tom", "Bob"] } ]]> </config> </rawDPValidator> </rawDPValidators> </dataPoint> <dataPoint name="LAST_NAME" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="LAST NAME"/> <dataPoint name="ADDRESS" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="ADDRESS"/> <dataPoint name="PHONE_NUMBER" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PHONE NUMBER"/> <dataPoint name="AGE" dataType="INTEGER" canEditValid="true" canEditViolated="true" displayName="Age"> <rawDPValidators> <rawDPValidator name="INVALID_IF_NULL" entity="NOT_NULL"/> // The name can be anything and it will appear in data audit/lineage <rawDPValidator name="INVALID_IF_NEGATIVE" entity="POSITIVE"> <lateBound>false</lateBound> // This is the default value if one is not specified </rawDPValidator> </rawDPValidators> </dataPoint> <dataPoint name="YEARLY_INCOME" canEditValid="false" canEditViolated="true" dataType="DECIMAL" displayName="YEARLY INCOME"/> <dataPoint name="TFN" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="TFN"/> <dataPoint name="PORTFOLIO_VALUE" canEditValid="false" canEditViolated="true" dataType="DECIMAL" displayName="PORTFOLIO VALUE"/> <dataPoint name="COMPANY_NAME" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY NAME"/> <dataPoint name="COMPANY_ADDRESS" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY ADDRESS"/> <dataPoint name="PROFILE_IMAGE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PROFILE_IMAGE"/> <dataPoint name="COMPANY_WEBSITE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY WEBSITE"/> <dataPoint name="XML_ROOT_DOC" canEditValid="false" canEditViolated="true" displayName="XML Root Doc" dataType="XML"/> <dataPoint name="JSON_ROOT_DOC" canEditValid="false" canEditViolated="true" displayName="JSON Root Doc" dataType="JSON"/> </dataPoints> <schemaAppliedProcessors> <groupTags> <groupTag>DEFAULT</groupTag> </groupTags> <metaData/> <rawDPValidators/> <rawDPProcessors/> <consDPValidators/> <consDPProcessors/> <dataBlockProcessors/> </schemaAppliedProcessors> <alerts/> </schema> </schemas> </apiroConf> -
We will now focus on these two records that are sourced from two different files.
Source file BAC FIRST_NAME LAST_NAME AGE TFN PORTFOLIO_VALUE customers_a.xlsx BAC222222 Bob Smith 35 222 222 222 80000 customers_b.xlsx BAC222222 Bob Smith 35 222 222 222 90000 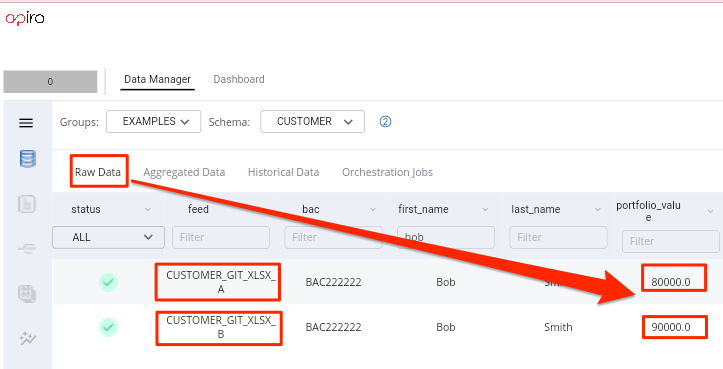
-
In this section we provide few different ways of consolidating the data points
PORTFOLIO_VALUEsourced from two different files:
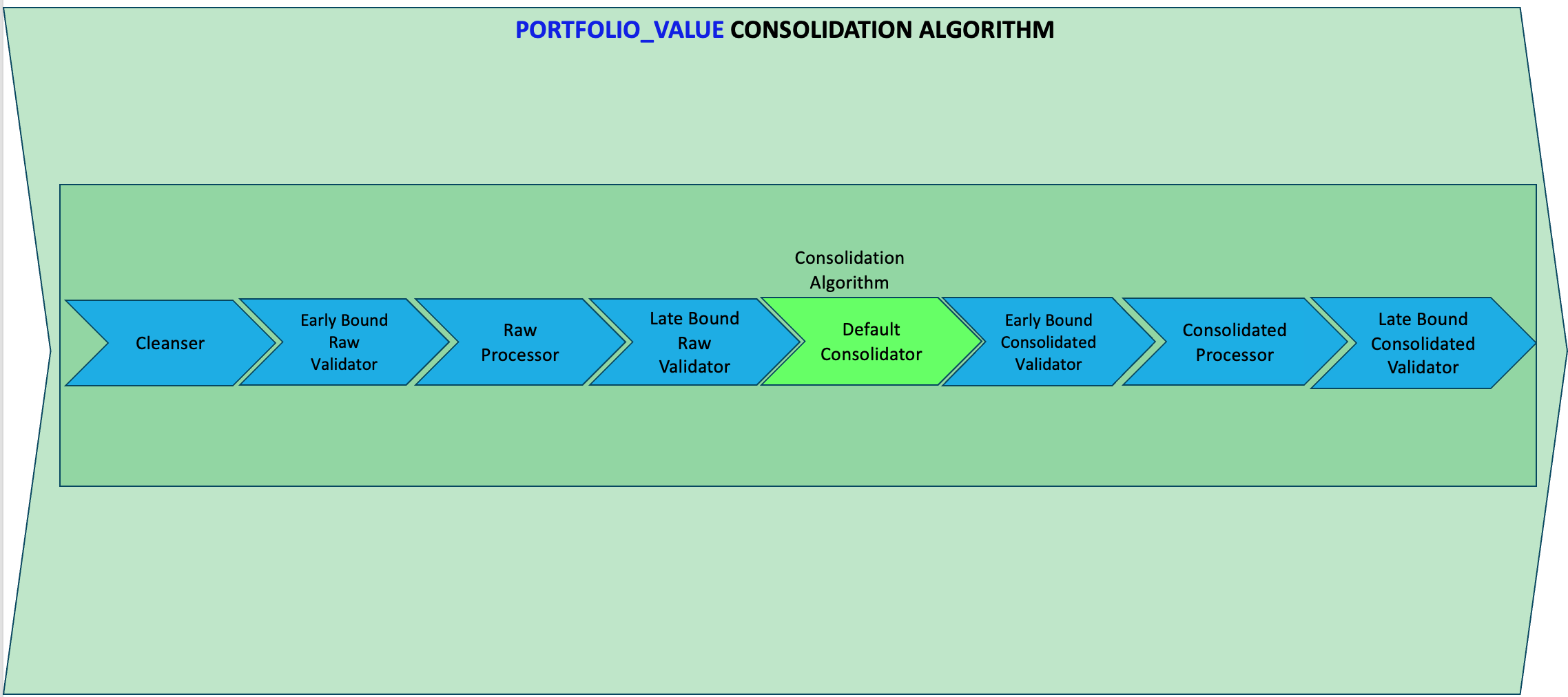
Default Consolidation Algorithm
- If no
<consolidationAlgorithm>is provided, then a default one will be implicilty provided by the platform. - The default consolidation algorithms for each data type can be found in the configuration reference guide under Consolidation Algorithms
- The default consolidation algorithms for
DECIMALdata types, calculates the MEAN value of all sourced values, as shown below(DECIMAL_MEAN). Note: Before proceeding, you must ensure that thePORTFOLIO_VALUE dataTypeisDECIMALand not aSTRING.
- Both options below are equivelant
-
OPTION 1: No explicity declaration of
<consolidationAlgorithm/>. It will implicitly include the default implementation.1 2 3
<dataPoint name="PORTFOLIO_VALUE" displayName="Investment Portfolio Value" dataType="DECIMAL"> <!-- <consolidationAlgorithm/> --> </dataPoint> -
OPTION 2: Explicit declaration of a predefined consoldiation algorithm
DECIMAL_MEAN. NOTE: In this case we have the opportunity to specify a custom name of this consolidation algorithm eg.PORTFOLIO_VALUE_MEAN. This will be included in data audit and data lineage. - Copy the
PORTFOLIO_VALUEdata point element below and override the corresponding element inSCHEMA_CUSTOMER.xml.1 2 3 4 5 6 7 8 9
<dataPoint name="PORTFOLIO_VALUE" displayName="Investment Portfolio Value" dataType="DECIMAL" canEditValid="false" canEditViolated="true" > <consolidationAlgorithm name="PORTFOLIO_VALUE_MEAN" entity="DECIMAL_MEAN"/> </dataPoint> - You must now push your updated SCHEMA_CUSTOMER.xml file to GIT and deploy as per the instructions provided at the bottom of this page to reload the configuration.
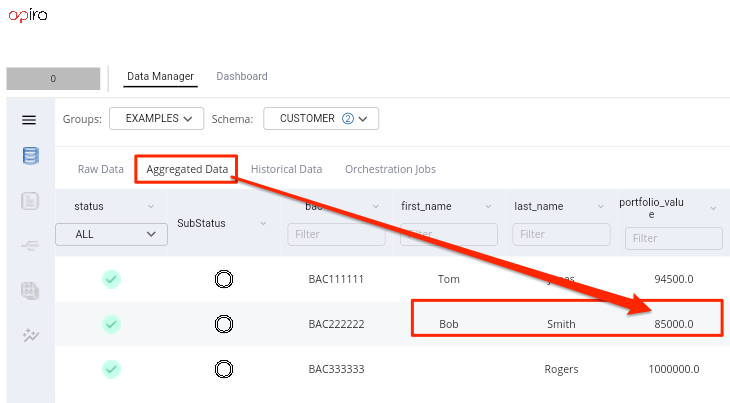
- The table below shows the result of the above configuration.
| Source file | BAC | PORTFOLIO_VALUE |
|---|---|---|
| customers_a.xlsx | BAC222222 | 80000 |
| customers_b.xlsx | BAC222222 | 90000 |
Consolidated PORTFOLIO_VALUE value |
85000 |
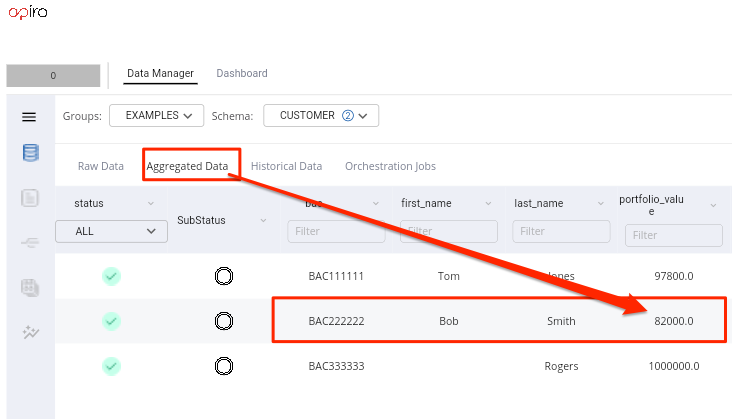
See how the UI will display the raw and aggregated values
Custom [Weighted Average] Consolidation Algorithm
- You may be wondering, what options do you have if there is no predefined Consolidation Algorithms that meets your requirements.
- In this case you can use GEN EXPRESS - Consolidation Algorithm,
- We will, configure a consolidation algorithm that calculates the weighted average of the values sourced from the two feeds.
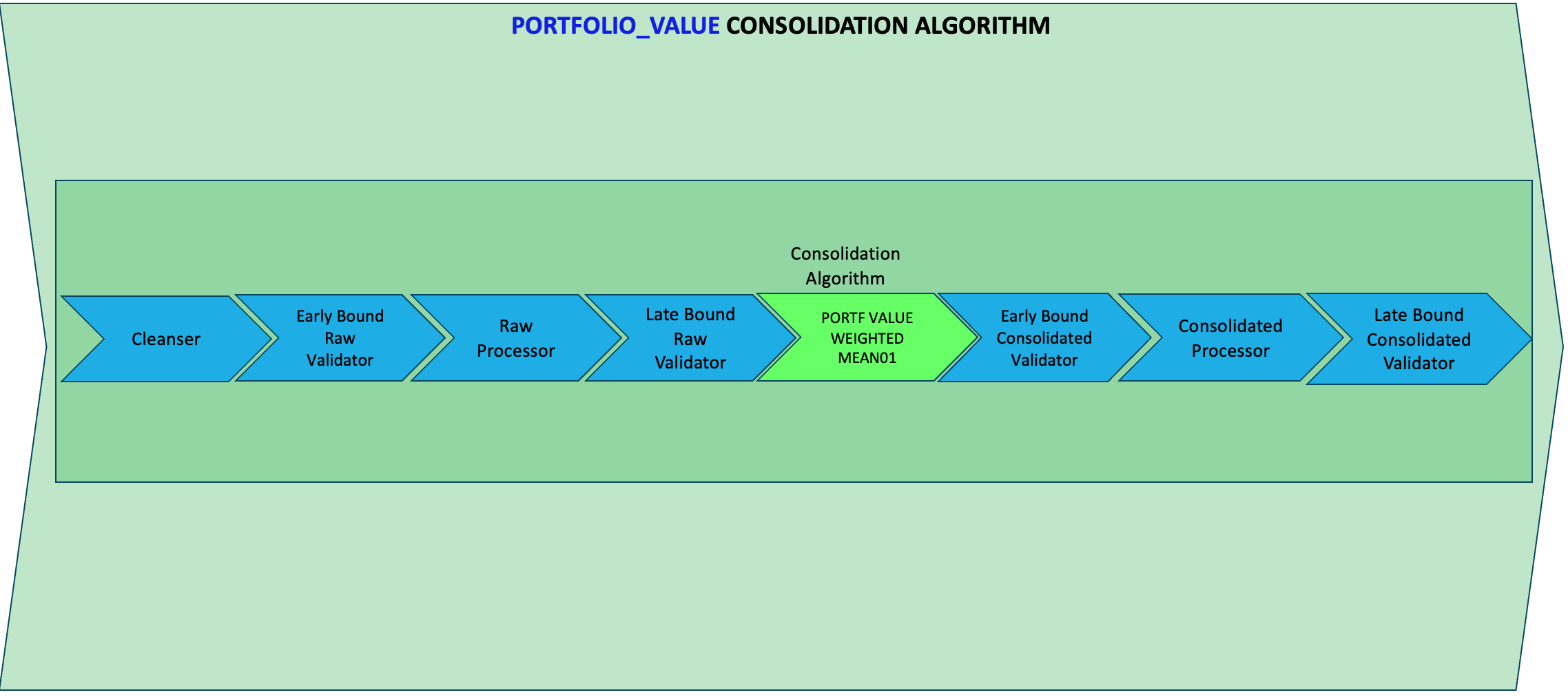
- Below we can see how we created a custom "weighted average" consolidation algorithm using a Groovy script.
- The groovy script can direcly refer to values from the specific feeds associated with the
CUSTOMERschema. - GEN_EXPRESS:
<consolidationAlgorithm name="PORTF_VALUE_WEIGHTED_MEAN_01" entity="GEN_EXPRESS">1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
<dataPoint name="PORTFOLIO_VALUE" displayName="Investment Portfolio Value" dataType="DECIMAL" canEditValid="false" canEditViolated="true" > <consolidationAlgorithm name="PORTF_VALUE_WEIGHTED_MEAN_01" entity="GEN_EXPRESS"> <config> <![CDATA[ #GRV{ def list= [] list.add(items.get("CUSTOMERS_A_XLSX")) list.add(items.get("CUSTOMERS_B_XLSX")) list.remove(null) if(list.size()==0) return 0; else if (list.size() == 1) return list[0] else { return (list[0].asDBL()*0.8 + list[1].asDBL()*0.2) } } ]]> </config> </consolidationAlgorithm> </dataPoint> - The table below shows the result of using the
GEN_EXPRES' predefined consolidation algorithm.
| Source file | BAC | Weight | PORTFOLIO_VALUE |
|---|---|---|---|
| customers_a.xlsx | BAC222222 | 0.2 | 80000 |
| customers_b.xlsx | BAC222222 | 0.8 | 90000 |
Consolidated PORTFOLIO_VALUE value |
82000 |
Consolidation Algorithm using Execution Domains
- You may still be wondering, "but what if I have requirement so complex and specialised that cannot even be implemented with " GEN EXPRESS - Consolidation Algorithm.
- TODO In this case, you will use
Execution Domains. - TODO See
Execution Domainsfor an example.
Configuration files
Completed configuration files
- This is the completed CUSTOMER schema configuration file that add the consolidation algorithms discussed above. Notice how simple and quick it was to add out of the box and custom data consolidators in a single configuration using the existing pre wired pipelines, audit and data lineage features.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128
<?xml version="1.0" encoding="UTF-8"?> <apiroConf version="1" xmlns="http://apiro.com/apiro/v1/root"> <groups/> <loadOrder>15</loadOrder> <schemas> <schema defBacked="false" historical="false" name="CUSTOMER"> <groupTags> <groupTag>EXAMPLES</groupTag> </groupTags> <metaData/> <identityKeys> <identityKey>BAC</identityKey> </identityKeys> <!-- Data Point descriptions --> <dataPoints> <dataPoint name="BAC" dataType="STRING" canEditValid="true" canEditViolated="true" displayName="BAC"> <nullable>false</nullable> <metaData> <item name="piiClassification"> <simpleValues> <simpleValue>High Risk</simpleValue> </simpleValues> </item> </metaData> <!-- BAC data point processors --> <rawDPValidators/> <rawDPProcessors/> <!--consolidationAlgorithm></consolidationAlgorithm --> <consDPValidators/> <consDPProcessors/> </dataPoint> <dataPoint name="FIRST_NAME" dataType="STRING" displayName="First Name" canEditValid="true" canEditViolated="true"> <rawDPValidators> <rawDPValidator name="IN_BAC_SET_CHECK " entity="IN_SET"> <config> <![CDATA[ { ignoreCase : true, options : [ "Tom", "Bob"] } ]]> </config> </rawDPValidator> </rawDPValidators> <consDPValidators> <consDPValidator name="INVALID_IF_CONSOLIDATED_NULL" entity="NOT_NULL"/> </consDPValidators> </dataPoint> <dataPoint name="LAST_NAME" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="LAST NAME"/> <dataPoint name="ADDRESS" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="ADDRESS"/> <dataPoint name="PHONE_NUMBER" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PHONE NUMBER"/> <dataPoint name="AGE" dataType="INTEGER" canEditValid="true" canEditViolated="true" displayName="Age"> <rawDPValidators> <rawDPValidator name="INVALID_IF_NULL" entity="NOT_NULL"/> // The name can be anything and it will appear in data audit/lineage <rawDPValidator name="INVALID_IF_NEGATIVE" entity="POSITIVE"> <lateBound>false</lateBound> // This is the default value if one is not specified </rawDPValidator> </rawDPValidators> </dataPoint> <dataPoint name="YEARLY_INCOME" canEditValid="false" canEditViolated="true" dataType="DECIMAL" displayName="YEARLY INCOME"/> <dataPoint name="TFN" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="TFN"/> <dataPoint name="PORTFOLIO_VALUE" displayName="Investment Portfolio Value" dataType="DECIMAL" canEditValid="false" canEditViolated="true" > <consolidationAlgorithm name="PORTF_VALUE_WEIGHTED_MEAN_01" entity="GEN_EXPRESS"> <config> <![CDATA[ #GRV{ def list= [] list.add(items.get("CUSTOMERS_A_XLSX")) list.add(items.get("CUSTOMERS_B_XLSX")) list.remove(null) if(list.size()==0) return 0; else if (list.size() == 1) return list[0] else { return (list[0].asDBL()*0.8 + list[1].asDBL()*0.2) } } ]]> </config> </consolidationAlgorithm> </dataPoint> <dataPoint name="COMPANY_NAME" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY NAME"/> <dataPoint name="COMPANY_ADDRESS" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY ADDRESS"/> <dataPoint name="PROFILE_IMAGE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="PROFILE_IMAGE"/> <dataPoint name="COMPANY_WEBSITE" canEditValid="false" canEditViolated="true" dataType="STRING" displayName="COMPANY WEBSITE"/> <dataPoint name="XML_ROOT_DOC" canEditValid="false" canEditViolated="true" displayName="XML Root Doc" dataType="XML"/> <dataPoint name="JSON_ROOT_DOC" canEditValid="false" canEditViolated="true" displayName="JSON Root Doc" dataType="JSON"/> </dataPoints> <schemaAppliedProcessors> <groupTags> <groupTag>DEFAULT</groupTag> </groupTags> <metaData/> <rawDPValidators/> <rawDPProcessors/> <consDPValidators/> <consDPProcessors/> <dataBlockProcessors/> </schemaAppliedProcessors> <alerts/> </schema> </schemas> </apiroConf>
Deploy config files
- Follow these steps Config Deployment to deploy and start using your configuration files.