Key Concepts
Data Organization and Processing
The following summary will help you to understand how data is organised and processed in Apiro.
DataBlocks and DataPoints
Datablocks are the primary unit of information representation. They can be thought of, as the equivalent of a table row in a relational database. Just like SQL database tables they are also represented and scribed by a Schema. Datablocks comprise one or more DataPoints, which are individual units of data.
Just like relational databases, DataBlocks usually have an explicit identity, identified by the values of one or more of its DataPoints.
Apiro has an inbuild facility to source the same conceptual data from multiple providers and aggregate it in some defined way either by intersection or union to construct a whole resultant DataBlock. As such, DataBlocks come in two types:
Raw DataBlocks - Represent raw unprocessed data ingested from external sources Aggregated DataBlocks - Aggregated DataBlocks are created from the merging of the corresponding Raw DataBlocks possessing the same identity.
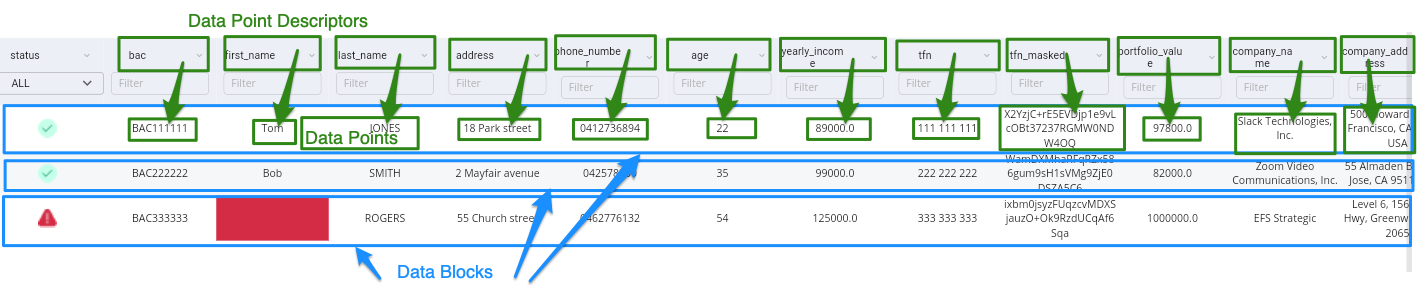
DataPoints
DataPoints are the smallest unit of representation of a single fragment of information. A DataPoint is roughly the equivalent of a single table column in a relational database. As stated above, DataPoints are aggregated together into logic units to make up a DataBlock, where DataPoints fundamentally related to each other in some way together make a DataBlock. DataPoints are of a particular type, and currently Apiro supports the following datatypes for DatPoints.
DataTypes
- STRING - unicode strings
- INTEGER - 64 bit signed integer values
- DECIMAL - decimal values with an unbounded integer component and a system set number of decimal places (default 8)
- JSON - native JSON encoded data
- XML - native XML encoded data
- BLOB - arbitrary binary objects (for performance, these are stored outside of the document structure and refereed to via a reference id)
Schemas
Apiro Schemas, just like relational database schemas, put structure around the form of DataBlocks to provide some level of consistency. They also define the processing steps that make up the processing pipeline for the schema. Apiro borrows a lot of the concepts from programming and both DataPoints and DataBlocks can inherit behaviour, in the case on DataPoints by extending what are called DataPoint Templates, and in the case of DataBlocks by either extending other DataBlock Schemas or by incorporating Schema Mixins (covered in detail later)
DataSources
To process data, Apiro needs to get a hold of it. To do this, it makes use of a concrete implementation of an abstraction called a DataSource. A DataSource simply obtains a 'bag of bytes' from somewhere and returns it to its caller with an indication of its possible type by means of a Content-Type or MimeType indicator.
DataSinks
To be useful at all, Apiro needs to provide data it processes to external consumers of the data. To do this, it makes use of a concrete implementation of an abstraction called a DataSink. A DataSink simply receives a 'bag of bytes' from its caller and does 'something' with it, presumably sending it somewhere for some useful purpose (mostly - we have a DataSource called NULL which does nothing to it, but we won't go into that here).
Violations
an Apiro violation can be thrown on a data point for any these reasons: data sourced by a dataFeed is not compatible with the data type value (INTEGER, BOOLEAN, STRING, etc.) of the associated schema data point. a violation is thrown by a raw validator within a schema data point a violation is thrown by a consolidated validator within a schema data point invalid or missing config for processors with config requirements. Requirements are shown for each processor in the predefined processors section.
A violated data point will cause the entire data block to become violated.
When a data point is violated, it is an indicator that the data within it is invalid or otherwise undesirable.
Given below is an example of what a raw violation looks like in the Apiro UI:
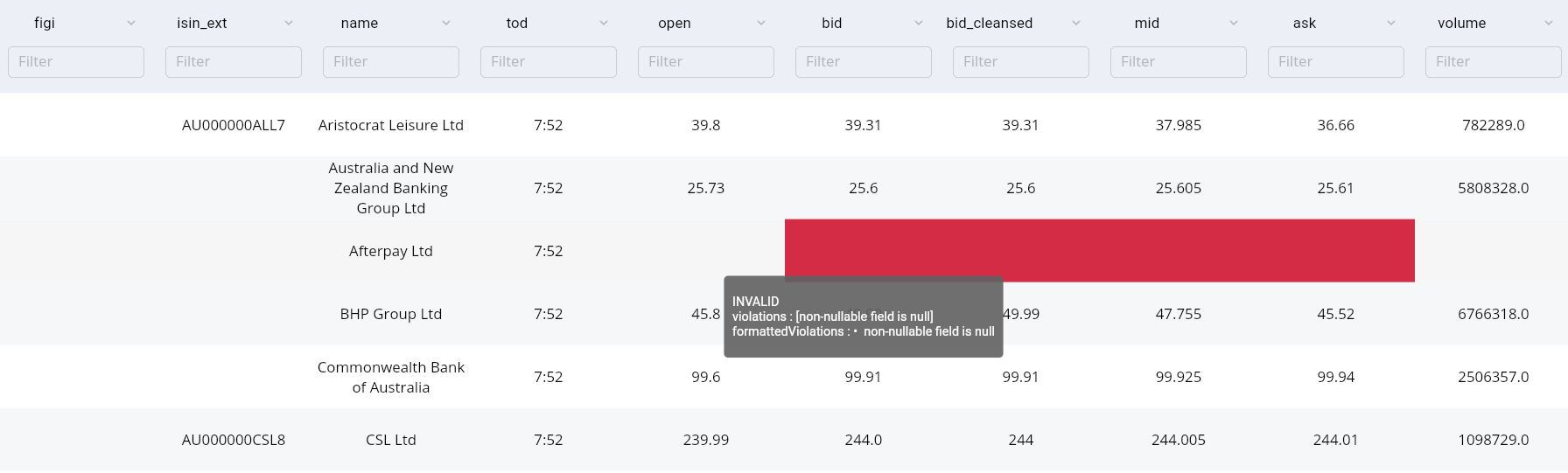
The status for this row will also appear as violated:
Load Order
For a typical use case where we are sourcing, processing and distributing data we will normally need the following entities.
- Schema or Datblock Collection
- Data Feed (Is always be associated with one schema)
- Data Source (Is associated with 0 to many Data Feeds)
- Data Sink
- Data Distribution (Is associated with 1 or many schemas, 1 or many Datablock collections and 1 or many Data Sinks)
Therefore, the above configurations for each entity needs to be loaded in the correct order.
You should not have to update the default load orders but in the event you specific use case requires a different load order then this can be achieved
by modifying the load order in each file as shown below.
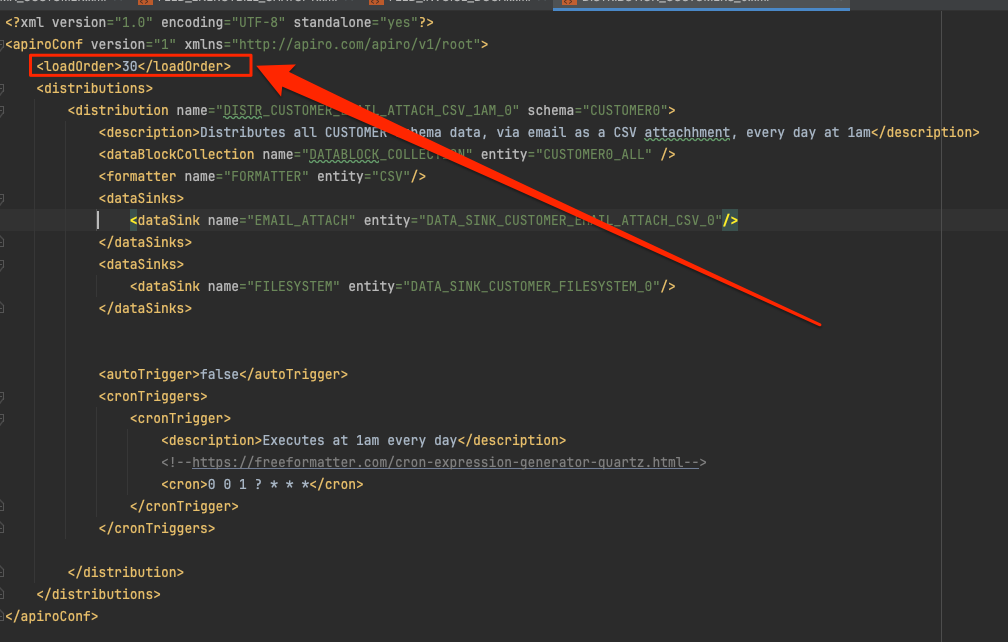
An entity with a smaller load order is loaded first. Therefore you need to ensure
- All
Schemas,Datablock CollectionsandData Sourceshave lower order thanData Feeds,Data SinksandData Distributions) - All
Data Sourceshave lower order thanData Feeds,Data SinksandData Distributions) - All
Data Feedshave lower order thanData SinksandData Distributions) - All
Data Sinkshave lower order thanData Distributions) - For example you could specify the following
- Schemas, Datablock collections and Data Sources load order: 1-15
- Data Feeds load orders: 16-20
- Data Sinks: 21-25
- Data Distributions: 26-30
Distributions
Distributions are the entities used to distribute data to downstream systems. A distribution uses 1. Schema or Datablock collections to specify the data to be included 2. A set of Data Points to provide a fine-grained control of the data to be included. 3. A number of Data Sinks to specify all the downstream systems. 4. A number of cron schedules to specify when the data to be auto distributed.
Please refer to the Configuration guide for Data Distributions for more details.
Datablock Collections
A Datablock collection is an entity which provide data selection criteria and the datablock level. Please refer to the Configuration guide for Datablock Collections for more details.
GitOps Configuration
Apiro is a GitOps based platform. Everything needed to bootstrap an Apiro instance is pushed and pulled from a Git repository. The obvious and very powerful advantages of a GitOps based platform
Consistency: Ensures uniform deployment across environments using declarative configurations stored in version-controlled repositories, reducing configuration drift.
Automation: Enables automated deployment and management of infrastructure through CI/CD pipelines, eliminating manual intervention and reducing errors.
Visibility: Maintains a clear, auditable history of changes through Git repositories, making tracking, troubleshooting, and auditing straightforward.
Rollback: Allows rapid, reliable rollbacks to previous configurations if issues arise, minimizing downtime and enhancing reliability.
Collaboration: Promotes collaboration among teams by using Git branching, pull requests, and reviews, ensuring peer validation and knowledge sharing.
Scalability: Simplifies the scaling of infrastructure across multiple clusters or regions, allowing for efficient multi-cloud or hybrid-cloud setups.
Security: Strengthens security by limiting direct access to production systems, ensuring all changes are reviewed and validated through version control.
Compliance: Supports compliance and governance efforts by providing an auditable trail of all infrastructure modifications.
Integration: Integrates seamlessly with existing DevOps tools and workflows, helping teams leverage their current expertise and practices.
Self-healing: Facilitates self-healing infrastructure by continuously syncing the actual state with the desired state defined in the repository, automatically fixing configuration drifts.
Everything has MetaData and Groups!
Every entity in the platform has the ability to use metadata and be assigned to groups.
There are obvious advantages of this approach but not limited to
Organization: Streamlines data management by offering a clear structure for data classification.
Discovery: Enhances data searchability, making it easier to find relevant information.
Context: Offers meaningful context, aiding in understanding data origin, usage, and relationships.
Quality: Facilitates data validation and accuracy by tracking data lineage.
Governance: Helps enforce data security and compliance standards effectively.